Did you try the examples from my previous post A Taste of Regular Expressions?
Practical skills (what we call “experience” or “know-how” in Korea) don’t develop just from understanding the method.
You gain experience by trying once, failing twice, and getting stuck three times.
This time, let’s work through some regex examples that you can use directly in real work.
Regular expressions start with patterns and end with patterns.
Regex is expressing those patterns using a defined syntax.
Practical Regular Expressions
Formatting
Let’s start with an easy exercise.
You’re creating an address book at work and collected names and mobile phone numbers from all employees.
When you open the file, you notice the phone number formats are all over the place.
It doesn’t matter when people read it, but it triggers the perfectionist hiding inside you.
Yes, you want to standardize the format.
010-1234-5678
01023456789
010.3475.9865
010 9958 4645
- Let’s standardize to the first format.
- The separators vary, but the pattern is the same:
3 digits+4 digits+4 digits. - So let’s give it a try.
- Find:
(\d{3}).*?(\d{4}).*?(\d{4}) - Replace:
$1-$2-$3
- Find:
- Then you get this result:
010-1234-5678
010-2345-6789
010-3475-9865
010-9958-4645
- In regex,
(........)means a group. Groups are mainly used in two ways:- As a group like
(Seoul|Daejeon|Daegu|Busan)to indicate multiple possible characters in that position - And like in the phone number example, to reuse the characters in the group when replacing
- When reusing characters, you denote which group it is in the replacement regex using
$1.
- As a group like
- In regex, replacing
(........)groups with$1is called ‘regex substitution’ or ‘regex replacement’. - In real work, just knowing this regex substitution alone can save you tremendous amounts of time.
- Let me continue with the explanation.
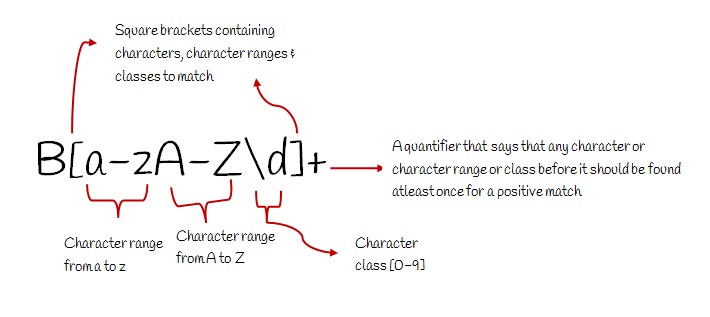
\dmeans one digit.- So how do you write 3 digits? Yes, you write it like
\d\d\d. - Writing
\d\d\d...for 10 digits is tedious, so you specify the count like\d{10}. - So
\d{3}means 3 digits, and\d{4}means 4 digits. - Wrap this in group parentheses to get
(\d{3}), which you can then reuse in the replacement.
- So how do you write 3 digits? Yes, you write it like
- Let’s break down the
.*?part piece by piece.- The period
.means 1 character. It includes any single character like-,a,9, and even spaces. - The asterisk
*means ’the preceding character may or may not exist’. So.*means ‘any 1 character may or may not exist’. - The question mark
?means to find the shortest pattern. So.*?means ‘any 1 character may or may not exist, up until the pattern that follows’.
- The period
- In the replacement,
$1refers to the first group (3 digits),$2to the second group (4 digits), and$3to the third group (4 digits).- The
-between groups is whatever symbol you prefer to display between the number groups. - If you put the replacement regex as
$1/$2/$3, the result would be ‘010/1234/5678’, right? - You can also change the group positions, or use one group multiple times.
- The
- Since we’re on the topic, let’s do an example of changing group positions or using them multiple times.
Regex Substitution
Everyone in Korea knows that King Gwanggaeto’s era name is written like ‘Yeongnak (永樂) 12th year’.
How would you separate the Korean and Chinese characters to change it to ‘Yeongnak 12th year (永樂 12th year)’?
Using the groups we discussed above, you can change thousands of words at once with a pattern.
Real-world data is naturally inconsistent, like this:
영락(永樂) 12년
장수왕(長壽王)9년
의자왕(義慈王) 3
- Let’s give it a try.
- Find:
([가-힣]+?)\((.+?)\)[ ]*(\d{1,2})[년]* - Replace:
$1 $3년\($2 $3년\)
- Find:
- Then it changes to:
영락 12년(永樂 12년)
장수왕 9년(長壽王 9년)
의자왕 3년(義慈王 3년)
- Let’s break down the regex piece by piece.
- In
[가-힣],[]is a symbol that represents 1 character, right?가-힣means the range from the Korean character가to힣. So[가-힣]becomes 1 character that includes the entire range of modern Korean characters.- All lowercase English letters can be expressed as a range like
a-z, all uppercase asA-Z, all digits as0-9. - To find one Korean or English character, you can express it as
[가-힣|a-z|A-Z]. - In
([가-힣]+?), the parentheses on both sides indicate a group,+means one or more, and?means minimal. Combined, it means one or more Korean characters up until the next regex pattern.
- All lowercase English letters can be expressed as a range like
- In
\(and\), the\symbol is for a special purpose called ’escaping’. It’s a different symbol from the slash/.- Since we use parentheses
(....)to mean groups, this is the way to represent actual parentheses in the text. - Symbols used in regex like
(....),+,?are reserved as regex symbols, so we put the escape character\in front to mean ’this is not a regex symbol, just a character’.
- Since we use parentheses
(.+?)is a group that matches any character one or more times, up until the next regex pattern.[ ]*means a space character may or may not exist.(\d{1,2})is a group meaning 1 or 2 digit numbers.[년]*means the character ‘년’ may or may not exist.- Let’s break down the replacement regex
$1 $3년\($2 $3년\).$1is the first group,$2is the second group,$3is the third group, right?\(and\)are expressing parentheses as actual text.- In the example
영락(永樂) 12년,$1is영락,$2is永樂,$3is12, so replacing with$1 $3년\($2 $3년\)gives us영락 12년(永樂 12년). - If you want to express the parentheses part as superscript on a website, you could change the replacement regex like this:
$1 $3년<sup>$2 $3년</sup>
Tip: Comparing Before and After Text (Diff)
Are you starting to find regex a bit fun?
If you’re quick with your hands, you might be thinking:
It’s faster for me to manually edit about 200 items.
But there are two problems.
One is that in real work, you’ll surprisingly often need to modify far more than 200 items,
and the other is that people make more mistakes than you’d think. (Yes, that includes me.)
So when you use regex replacement, you can change everything at once without mistakes.
Also, when doing regex replacement, the sample parts you reviewed may have changed exactly as you intended,
but parts at the end of the document or areas you didn’t check often get changed incorrectly.
So you need to compare the original and modified versions to minimize mistakes.
We call comparing the original and modified versions ‘diff’ for short.
There are many online tools, so it’s good to develop the habit of comparing the original and modified text.
Besides online tools, I recommend Meld as an installable program. I’ll post about how to use Meld separately later.